
编者按:在本文作者看来,自1980年代以来,计算经历了集中式计算、分布式计算、云计算和智能计算时代。而从2020年以来,计算则进入了AI计算新时代,在作者看来,在跨入了新时代,因为新的需求,将催生芯片架构发生新的转变,这就给大家所说的“大芯片”带来新的机会和发展方向。在本文中,作者将深入浅出地阐述其观点。
以下为文章正文。
“计算”的演变:新时代提出“芯”要求
在详细介绍计算要求之前,我们先要了解一下这几个“计算”。
集中式计算:PC (personal computer,个人计算机)一词源自于1981年IBM的第一部桌上型计算机。集中式计算主要是通过不断增加处理器的性能来增强单个计算机的计算能力。
分布式计算:是一种计算方法和计算形态,和集中式计算是相对的。随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以共享稀有资源,平衡复杂,节约整体计算时间,大大提高计算效率和资源利用率。
云计算:云计算早期,就是简单的分布式计算,解决任务分发,并进行计算结果的合并。因而,云计算又称为网格计算。现阶段所说的云服务已经不单单是一种分布式计算,而是分布式计算、效用计算、负载均衡、并行计算、网络存储、热备份冗杂和虚拟化等计算机技术混合演进并跃升的结果。

智能化转型和计算范式
智能计算:是一种通用算力和AI算力的融合,计算和通信两个领域的融合开创了智能计算的新天地,使得通用算力和AI算力的异构成为现实,从而支撑了大量以DNN为代表的AI应用。
AI新时代计算:今年3月15日,此前研发了ChatGPT的OpenAI公司,发布了新一代语言模型GPT-4,引起全球广泛关注。GPT4拥有超过1.6万亿个参数,而GPT3只有1750亿个参数(1.75e+11)。这意味着GPT4可以处理更多的数据,生成更长、更复杂、更连贯、更准确、更多样化和更有创造力的文本。
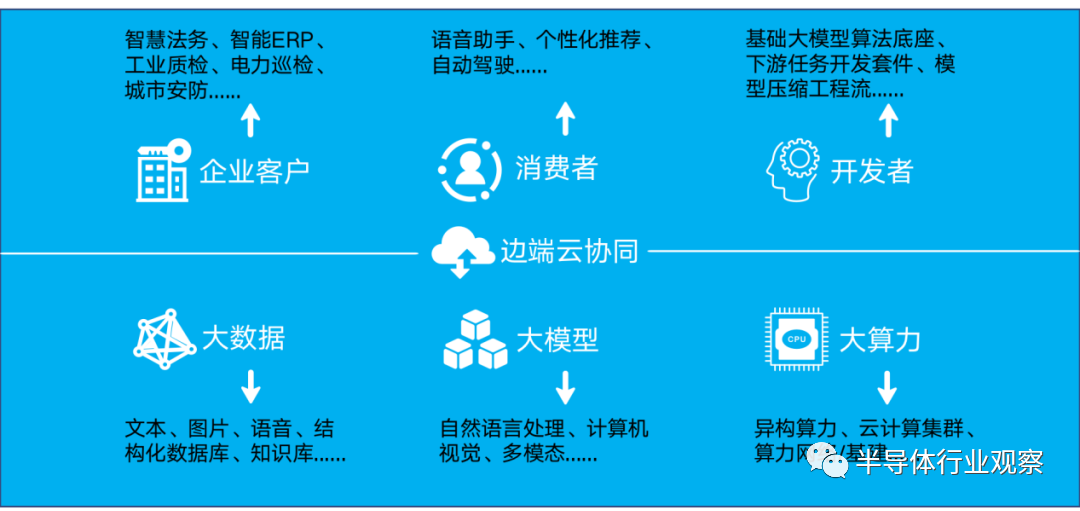
智能化转型:加速大数据、大模型、大算力融合
随着大模型的快速发展和部署,人工智能正在推动各行各业的变革,从图片文字识别、推荐系统、视频内容搜索、文字翻译甚至到云端应用场景都与人工智能息息相关。未来的人工智能上游有三大场景:企业应用、消费者和开发者,底层基础设施有三大支柱:大数据、大模型和大算力,中间层则需要端边云协同。

(端边云协同:云侧中心化,边侧算力下沉,端侧智能化)
随着 5G 、AI和IOT时代的到来,仅靠云计算中心集中存储、统一计算或集中式的模式已经无法满足终端设备对于时效、容量、算力的需求。端边云协同方案,将 AI 算力下沉到边缘,在靠近终端用户的边缘集群进行数据本地处理,减少数据传输成本和存储成本,并将 AI 算力下沉到边缘,提高本地算力和边缘智能,处理实时性要求高的场景需求;边缘侧和云端数据保持同步,云端集群提供更强大的算力支撑,针对实时性要求低、模型复杂的场景需求,提供复杂模型训练、配置、部署,为边缘集群提供能力传递。
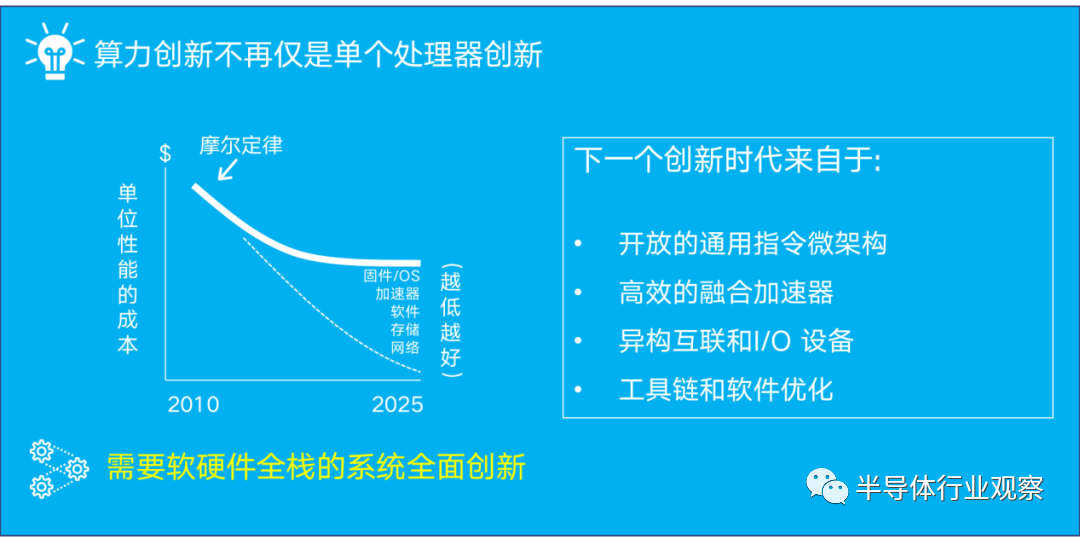
AI新时代对数据中心算力创新的要求
在1965年Gordon Moore提出摩尔定律到今天的近58年中,摩尔定律的效率已经逐步衰退到接近失效。2017年在一篇著名的 "计算机体系结构的新黄金时代 "的论文中,John Hennessy和David Paterson追溯了计算机体系结构的历史,并描述了随着扩展的结束而面临的挑战。他们认为领域专用架构或领域专用加速器(DSA)是计算机架构的新机遇。面向下一个计算时代,需要软硬件全栈的系统全面创新,重点要在如下几点突破:开放的通用指令微架构,高效的融合加速器,异构互联和I/O 设备,工具链和软件优化。
从计算发展史,看未来计算新范式
当IBM设计出最早的通用电子计算机IBM360,当程序员敲下第一行Hello World程序,计算便从单CPU开始了。然后为了解决更大规模的问题,分布式计算蓬勃发展了起来。它的计算核心基本都是CPU,是同构的。与此同时,单CPU的计算能力不断得到提高,多核,多线程,多层cache,片上加速器,原子性操作,Transaction Memory,位宽更宽,路数更多的计算单元。制造工艺也不断进步,65nm,45nm,22nm,14nm,7nm甚至到研发中的5nm,3nm,小小一块芯片上集成的晶体管数目在不断挑战极限。
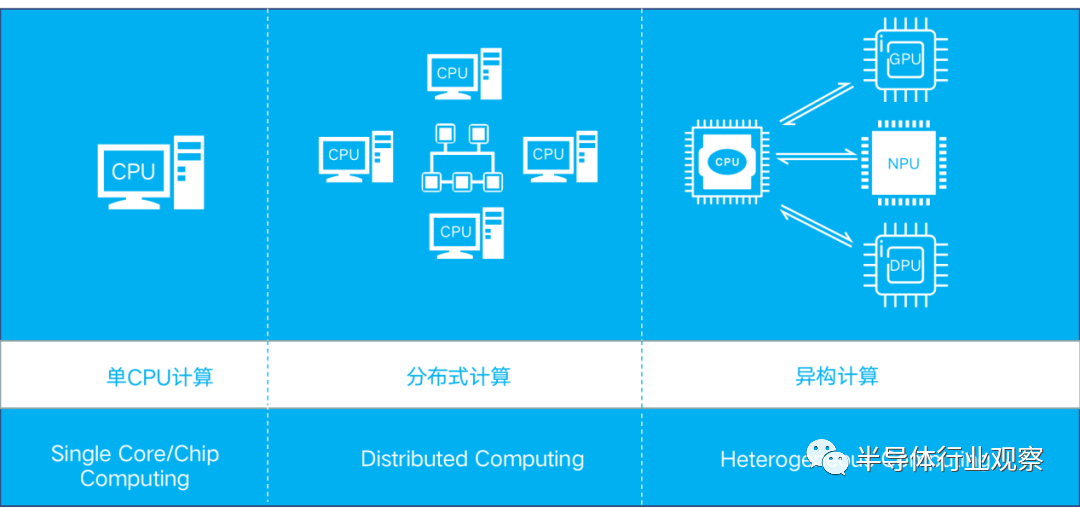
计算发展史:单核→多核→分布式→异构
“每过18个月,集成电路上的晶体管数目就会翻倍”,这是著名的摩尔定律。可是,时代发展到了今天,随着人类不断接近物理的极限,摩尔定律的增速也逐渐平缓,当前需要靠异构计算满足高速增长的计算需求;那未来的计算模式会会如何,怎样满足下一代人工智能的快速发展?
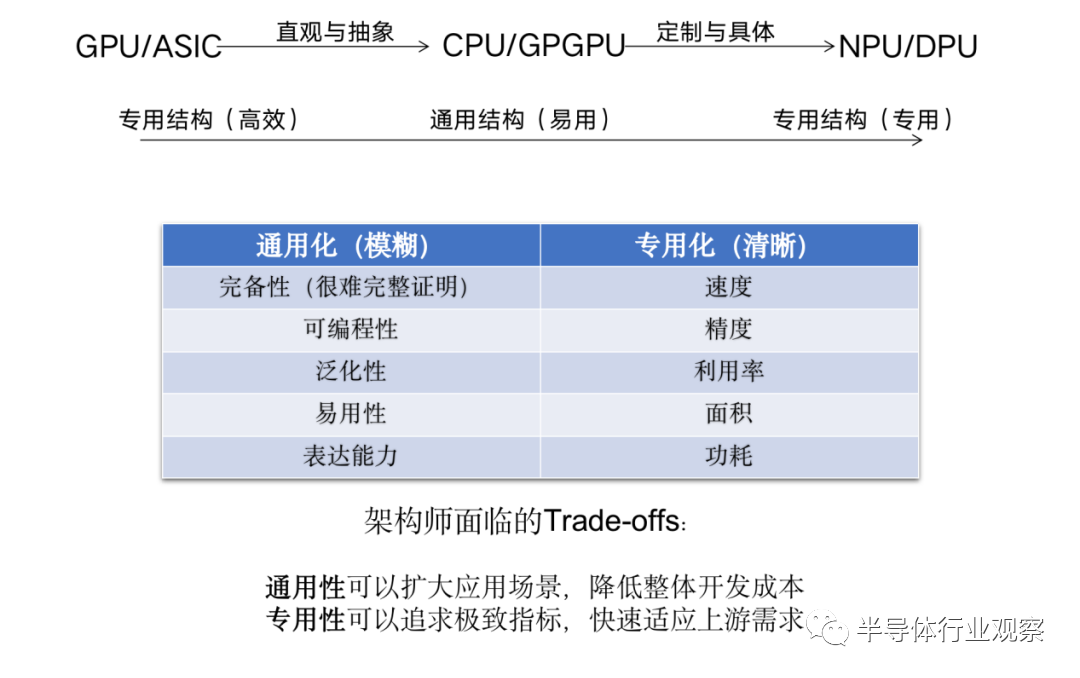
计算范式:通用性vs专用性
计算架构的演进是从以 CPU 为中心,逐步到现在的 DSA 对等架构,可以称为XPU (包括 CPU、GPU、NPU、DPU、QPU 等,QPU 即量子计算单元)。未来会怎样继续演进呢?会出现怎样的新计算架构?
在技术延长线上,操作系统要持续去攻克 DSA 架构下的 XPU 异构算力间的高效协同与资源共享能力。但可以看到,DSA 的原生弊端正在逐步显现,一方面是厂家需要看护多种多样的硬件架构,维护成本极其高,且存在功能重叠的问题。而且 DSA 很多是为特定运算设计的,稍微改变运算的形状 (shape),可能会导致效率有很大下降。此外,还存在软件栈难共享,XPU 间协同调度效率低等问题。
没有专用结构就不可能有通用结构所产生的基础材料,就不可能延展到做成通用产品的芯片。没有通用结构就不可能有可以分层复用和清晰编程界面的接口,并通过泛化去扩展更多的应用场景和市场空间。泛化这个逻辑在商业市场是必需品,因为泛化能力意味着低成本,从而以正向的ROI(投资回报)做为商业闭环才能驱动技术长期稳健发展,历史上很多昙花一现的技术和产品,从指标上看都很好,但泛化能力有限,最终都倒在了商业闭环上。
按照牧村定律,业界有望诞生出新的计算架构。(牧村定律/牧村波动,日立公司总工程师牧村次夫 (Tsugio Makimoto) 在 1987 年提出,芯片架构的发展,总是在分层解耦和垂直整合之间交替摆动,大概每十年波动一次。牧村定律背后是性能功耗和开发效率之间的平衡。) 经过当下 DSA 这样的“分”之后,未来一段时间内,如果大部分的算力模型已定型,出于维护、成本、能力发挥等因素的考量,大家可能会自然想到,能否将各种 XPU 进行融合,甚至融合到同一个架构上去呢?这个新计算架构到底是什么,目前还需要进一步探索。
但不管怎么样,操作系统的计算范式可能会被重新定义,其底层的机制也将大幅重构。
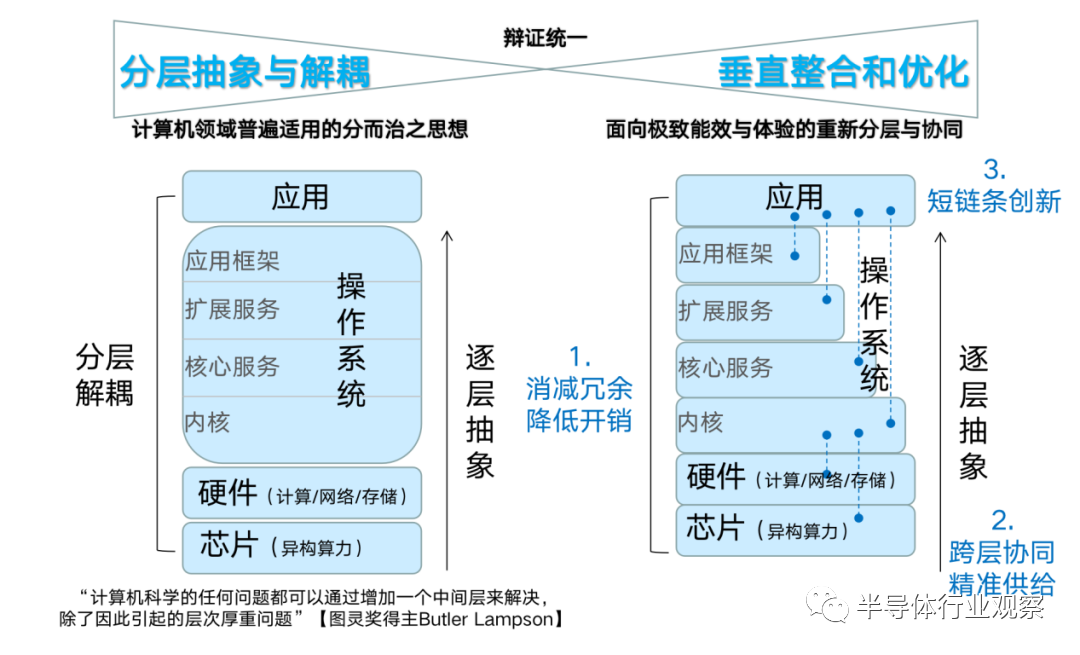
计算范式:分层解耦vs垂直整合
在华为计算2030中,曾有一章节介绍过,软硬件分层和整合的关系。具体来讲,软硬件垂直整合和分层解耦看似是两种不同的方法论,但实际是辩证统一的。分层抽象和解耦,是计算机领域普遍适用的分而治之思想。图灵奖获得者 Butler Lampson 提过这样一个大家熟知的理念,即“计算机科学的任何问题都可以通过增加一个中间层来解决”(其实是增加一个抽象来解决),但他后面还讲了一句话大家都常常忽视,“除了因此引起的层次厚重的问题”。
随着人工智能领域的快速深入发展,我们在很多场景中还是需要一些短链条式的创新。比如,操作系统的应用调用,可以分不同层级,使其调用到不同效率的接口。垂直整合是面向硬件与业务的重新分层与协同,并非走向“烟囱化”。在合理软硬分工协同上,应结合硬件与业务的特征,提供“短链条创新”。
产业界正在关注的三大热点
当然,垂直整合仍要坚持软件的平台化,构筑友好的生态,而不是走向自我封闭。目前做GPU、NPU、DPU及其他XPU的厂商无一例外的都在思考这一问题。这进而引出了业界正在广泛关注的三大热点话题:
热点1:ARM在通用场景加速替代x86,RISC-V正在加速构建ISA新体系

RISC-V主打开源(仅ISA)指令集架构,也就是说 RISC-V 指令集可以自由地用于任何目的,允许任何人设计、制造和销售 RISC-V 芯片和软件,而不必向任何公司支付专利费用。RISC-V的一大优点是模块化:芯片设计者可以根据自己的需求,对不需要的模块进行拆解;芯片设计模块化能够极大的提升产品的灵活度,使得设计与应用更加匹配。
RISC-V有很大的后发优势,但也要注意工具链、生态层面要做的功课依旧艰巨,特别是高性能领域。高性能领域如HPC、数据库、企业存储等不仅软件栈厚重,而且需要很深的行业知识沉淀。因而未来要避免生态碎片化,避免大家在同样的指令集架构下还去重复“造轮子”。因此在一些基础的编译工具链、操作系统,比如GCC/LLVM,Linux等,希望整个行业能够合力去共同打造,而不是说每个RISC-V厂家都要自己做一套,这其实是一个很大的浪费。
ARM 架构花了10年多时间从消费端到数据中心端逐步打造完整生态,RISC-V 未来在通用服务器场景有很大潜力,但也需要比较长时间去沉淀,短时间内更适合专用场景,其中AI推理将是极大的机会。
热点2:AI模型小型化和RISC-V架构不谋而合
通用+异构融合,即 Scaler小标量+SIMT大算力的指令集+微架构融合将是未来RISC-V 发力重点,面向AI推理侧应用产生巨大优势。
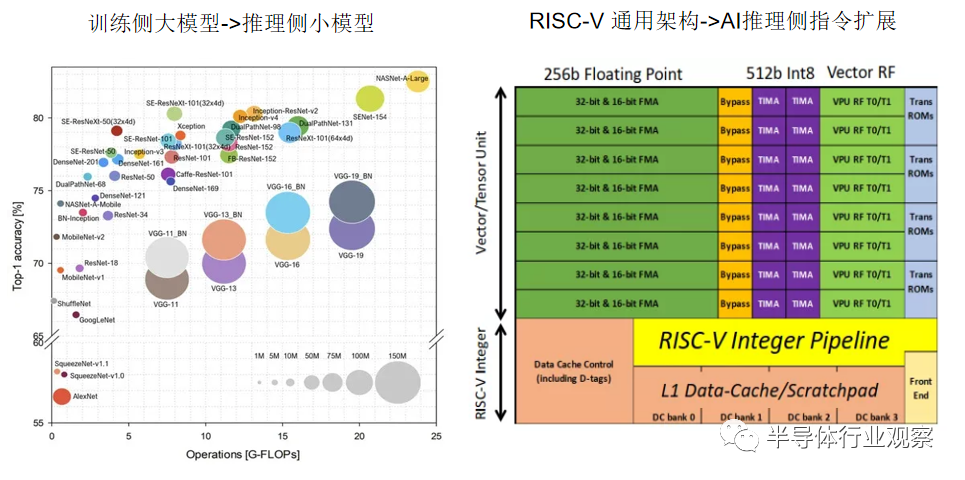
左图:GPU的发展,满足了大型 DNN 网络的内存带宽和计算能力的需求。由于计算能力的提高和可用数据量的增加,DNN 已经演变成更宽、更深的架构。DNN 中的层数可以达到数万层,参数达数十亿,研究人员很难在硬件资源(例如,内存、带宽和功耗)有限的便携式设备中部署 DNN。迫切需要在资源受限的边缘设备(例如,手机、嵌入式设备、智能可穿戴设备、机器人、无人机等)中有效部署 DNN 的方法。于是AI科学家们又开展AI模型小型化的研究,也就是用最少的参数量,最少的计算量去达到想要的模型精度。于是shufflenet、mobilenet、网络架构搜索 (NAS) 算法等轻量级神经网络结构开始被推出。能够在很少的参数量上去达到与大参数量模型接近的精度。同时神经网络的参数剪枝、参数量化、紧凑网络、知识蒸馏、低秩分解、参数共享、混合方式等等压缩技术与计算加速技术开始成为研究的热门。
右图:RISC-V 因其相对精简的指令集架构(ISA)以及开源宽松的 BSD 协议使得Fabless可以基于RISC-V架构进行任意的架构拓展与定制。相信RISC-V DSA可以利用其经典的CPU的编程模型与相对低成本获取的AI算力,加之标准RISC-V Vector拓展提供的通用算力。能够给AI推理场景下几十~几百T算力需求范围的AI产业应用带来全新的商业化硬件方案。RISC-V,其精简的架构使得芯片架构师们能够将更多的精力集中在性能特性上,而不是解决其他 ISA 的历史包袱和极端问题。除了标准的 RISC-V 指令外,RISC V 架构还支持自定义的指令扩展,如多周期张量指令和伴随的向量超越指令(vector transcendental instructions),为AI推理侧的很多应用提供高效支持。
比如近年来大热的Jim Keller所在的Tenstorrent有一个全面的路线图,包括基于RISC-V的高性能CPU小芯片和先进的AI加速器小芯片,它们有望为机器学习提供功能强大的解决方案,提供AI加速器和高性能CPU内核似乎是一种非常灵活的商业模式。
热点3:一致性异构总线和高速互联使得通用算力和异构算力紧密耦合
异构编程一直是整个异构计算系统中一个比较头疼的事情。通用算力和异构算力需要通过CPU上比较丰富的异构计算接口资源(NVLink/CXL/UCIE, etc)紧密相连,使得整个系统的内存在逻辑上可以被统一为一个更大的具有一致性的内存空间,可以同时供各种异构算力芯片来进行访问,这种一致性的模式可以让异构计算芯片之间更好的协同工作,从而提高整个系统的性能和功耗。
另外很重要的一点是,高效的异构一致性总线可以使编程的复杂度大幅度降低,程序员可以更多去关注计算分配本身,而不用去过多的考虑Memory去寻址的问题。因为整个系统具有统一的一致性内存模型,针对该模型,可以去设计专门对统一寻址的模型基础优化过的软件库。

一致性异构总线让XPU与CPU处理器协同更加紧密
如图所示,以CPU和GPU协同计算为例,CPU和GPU通过异构计算接口和总线紧密相连,CPU System memory和加速器Cache memory在逻辑上被统一为一个更大的具有一致性的内存空间, 可同时供CPU和GPU访问,使得编程复杂度得以降低,原因如下:1)整个系统具有统一的一致性内存模型;2)丰富的专门针对此异构计算架构进行优化的软件库 (OpenMP4.x, OpenACC, etc.)
特别是对于DSA专用芯片,有效算力(或可获得算力)往往尤其重要,直接决定应用的实际性能,而不是纸面上的算力(FLOPS 或 MACs)。为了更直观简单的量化分析有效算力,我们可以通过Roofline模型分析,这是由加州理工大学伯利克提出的用来建立当前计算平台在不同的计算强度(Operational Intensity)下能够达到的理论计算上限 。
如以上示意图所示:以CPU或GPU芯片为例,屋顶线模型(Roofline Model)中纵轴P代表芯片算力,单位是操作数每秒,横轴I代表AI或OI应用的计算强度(Arithmetic/Operational intensity),即单位内存交换用来进行了多少次计算,单位是操作数每字节。AI应用的计算强度可以由应用的计算量除以应用的访存量得到。
屋顶线模型可以体现出芯片的三个重要参数,它们分别是π代表了芯片的算力峰值,β代表芯片的内存带宽峰值,即每秒最多能完成的内存交换量,单位是字节每秒,亦即图中绿色斜线和X轴的夹角。第三个参数是Imax,代表芯片的计算强度上限,即π/β。此外图中曲线脊点(Ridge Point)代表了达到峰值算力所需的最小的计算强度。
屋顶线模型把平均带宽需求和峰值计算能力与吞吐量联系在一起,以计算强度上限Imax为界,划分出芯片的两个瓶颈区域,即图中内存受限区(Memory Bound)和计算受限区(Compute Bound)。
由此可知,一味通过简单粗暴堆砌硬件资源(MACs)提升算力(FLOPS)并不经济,而是结合提升总线/内存/接口整体效率,以差异化SoC的硬件形态并配合软硬件协同优化,来提升有效算力是面向真实应用产生价值的关键。
芯片工程,提升大算力的关键路径
随着 Chiplet、3D 堆叠、Wafer Scale Computing / Wafer on Wafer 等芯片技术的出现,单纯依靠摩尔定律的芯片工艺可能会演变为主要依靠芯片工程,成为提升算力密度的关键路径。
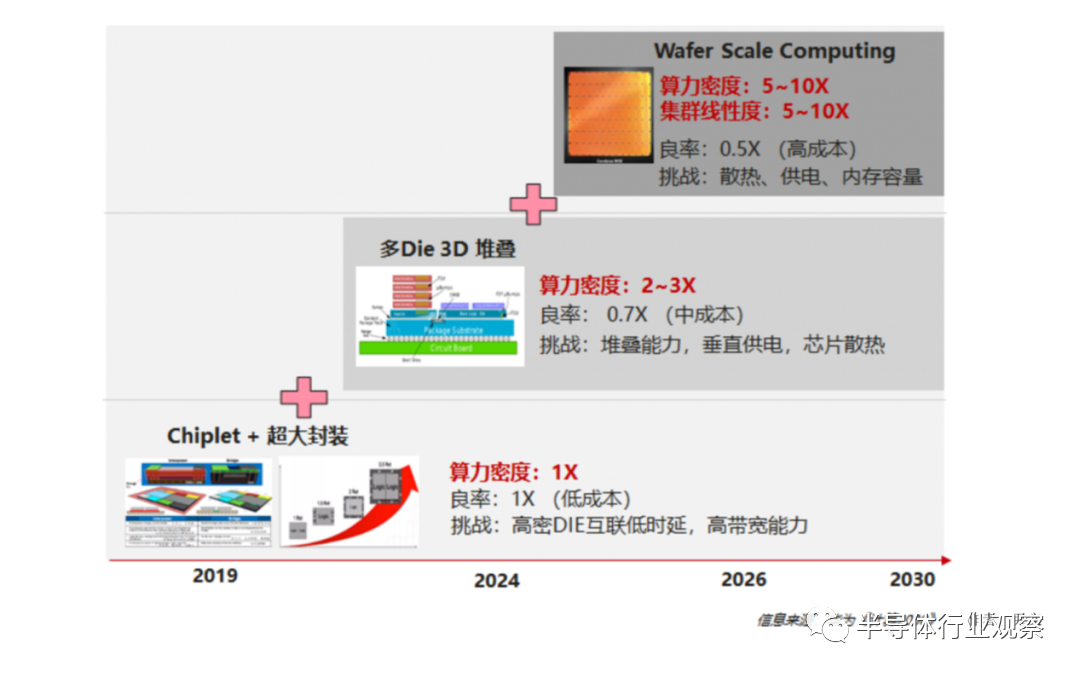
Cerebras 以其WSE-2 (Wafer Scale Engine)芯片而闻名,它是世界上最大的芯片之一,类似于一个8x8英寸的平板,每个平板包含2.6万亿个晶体管和85万个“人工智能优化”内核。特斯拉通过使用台积电芯片先进封装技术InFO_SoW,集成25个D1芯片的训练模块在人工智能训练芯片D1上,从而构建出Dojo超算系统的基本单元,到24年初,Dojo将成为全球最先进的5台超级计算机之一,Dojo的交付将加速自动驾驶FSD和人形机器人走进现实。

Cerebras & Tesla 面向大模型的Wafer Level 大芯片
以Tesla 的Dojo为例,他的特别之处在于,其D1 芯片 tile并非由多个小芯片所构成,而是单一包含354个核心的大芯片,专门针对AI和机器学习设计而成。之后,一个托架可以容纳6块D1 tile外加配套计算硬件,每台机柜可以安装两个这样的托架。这样算来,每机柜就将包含4248个核心,而由10台机柜组成的exapod共拥有42480个核心。基于CPU的超级计算机在相同空间中的核心数量肯定达不到这么多,GPU在这方面具有碾压性优势。而且由于Dojo专门针对AI和机器学习处理进行了优化,所以在同等数据中心空间之内,它比传统CPU或GPU超级计算机都要快上几个数量级。
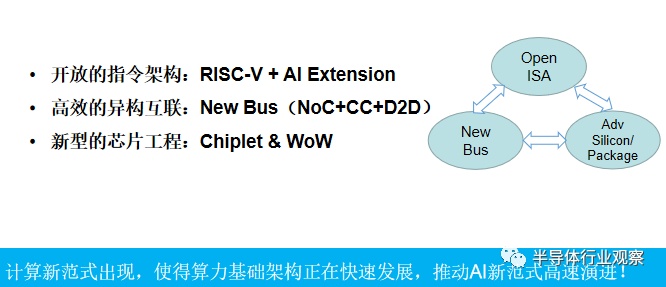
基于上述思考,笔者认为,开放微架构、异构互联、芯片工程高速将演进推动 “算力统一场”。
写在最后,一些展望
在行业内都在焦虑集成电路的发展受困于摩尔定律不断放缓并走向极限, John M. Hennessy和David A. Patterson (2017年图灵奖获得者)在2018年图灵讲座曾发表过:“计算机体系结构的黄金时代” (讲座视频:https://www.bilibili.com/video/av756320330/)。
当前,随着新应用、新技术的持续演进,特别是AI大模型、算力网络等快速推进,计算芯片新范式也随之出现,使得算力基础架构正在快速发展, 新的集成电路体系架构黄金时代也在加速到来,也将给芯片行业注入更多创新的机会。
未来的机会:重构计算体系结构,打造算力统一场,发展软件大生态

作者简介:
芯至科技副总裁、首席芯片架构师
参考文献
计算2030:https://www-file.huawei.com/-/media/corp2020/pdf/giv/industry-reports/computing_2030_cn.pdf
智东西公开课:https://baijiahao.baidu.com/s?id=1617359023882130982&wfr=spider&for=pc
特斯拉Dojo超算架构:https://mp.weixin.qq.com/s/vmNsRVwmi3Azo-bPDanc2g
计算机体系结构的黄金时代:https://www.bilibili.com/video/av756320330
*免责声明:文章内容整理自网络,芯司机转载仅为了传达一种不同的观点,不代表对该观点赞同或支持,如果有任何异议,欢迎联系。
- 还没有人评论,欢迎说说您的想法!



